Method
GROOT (Fusion via GRammian Optimal TranspOrT) fuses spectral and SSL representations for SHAC. Spectral features (MFCC, LFCC) are highly sensitive to NAC-induced distortions at the acoustic level, while SSL representations (Wav2vec2, UniSpeech-SAT, WavLM) capture broader temporal structure and variability in heart sounds. GROOT aligns these complementary representations using a novel grammian optimal transport mechanism that compares representations through their gram matrices rather than raw features.
Feature extraction
14-dim LFCC and 40-dim MFCC are extracted as spectral features. Wav2vec2, UniSpeech-SAT, and WavLM are used as SSL representations, each producing 768-dim features via average pooling over the final hidden layer.
1D-CNN and max-pooling
Each representation (R1, R2) is passed through a 1D-CNN block (32 filters) followed by max-pooling, then flattened and linearly projected to a 120-dimensional vector.
Gram matrix computation
Gram matrices GR1 = R1 R1^T and GR2 = R2 R2^T capture correlations between features and reflect global relational patterns, such as rhythm, across each representation space.
Grammian optimal transport (Gram-OT)
A cost matrix is built from the Frobenius distance between the two gram matrices, and the Sinkhorn algorithm computes an optimal transport plan to align the two representation spaces.
Fusion and classification
Transported features are concatenated with their original representations to form F1 and F2, passed through parallel FCNs, concatenated again, and classified by a final FCN with a sigmoid output for real-vs-spoof detection.
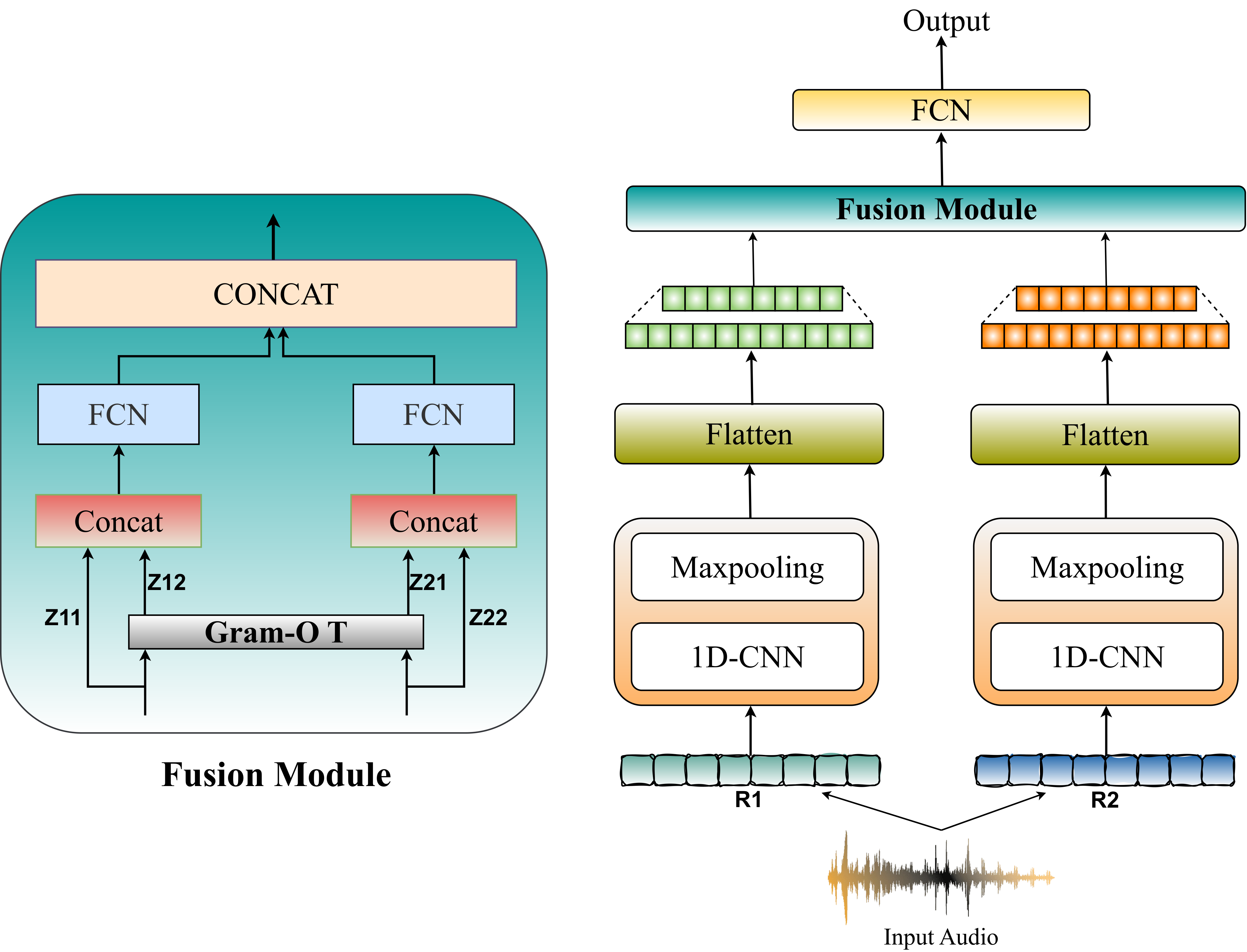
Figure: The GROOT framework. Two representation branches (R1, R2) are each processed by a 1D-CNN and max-pooling, flattened, and aligned via the Gram-OT fusion module before classification.
Gram-OT Alignment
The fused representations F1 and F2 are passed through FCNs with a dense layer of 80 neurons each, concatenated, and processed by a final FCN (120 and 30 neurons) with a sigmoid output layer for binary classification.
Synthetic Heart Sound Detection
Binary real-vs-spoof detection of neural-audio-codec-synthesized phonocardiograms.
Gram-OT Alignment
A novel grammian optimal transport mechanism aligning representations via their gram matrices.
Spectral + SSL
MFCC and LFCC capture acoustic-level codec distortions; WavLM and Wav2vec2 capture temporal structure.
1D-CNN + FCN
Lightweight CNN and max-pooling per branch followed by fusion and a fully connected classifier.
93.20% / 5.86% EER
GROOT with MFCC + WavLM sets a new SOTA for the SHAC task (Seen condition).
Robust heart sound CF detection
Establishes the first benchmark and baselines for detecting NAC-synthesized heart sounds.