SATYAM
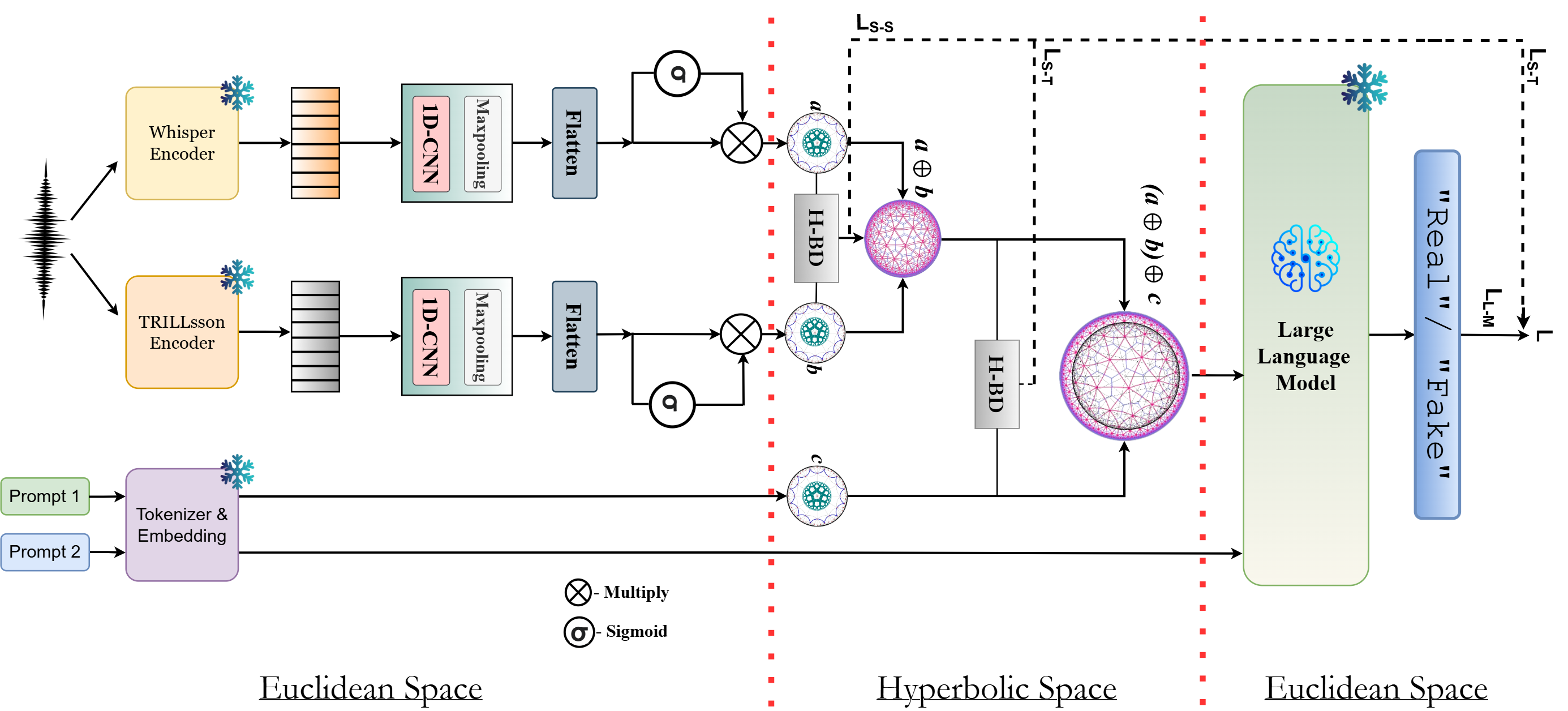
SATYAM is a supervised hyperbolic ALM that formulates CF detection as a conditional generation task. Given an input speech utterance, SATYAM extracts complementary semantic and paralinguistic representations, fuses them in hyperbolic space via Bhattacharya distance alignment, and conditions a frozen LLM decoder to generate a one-word verdict: "Real" or "Fake". Total trainable parameters: ~3.75M.
Dual Audio Encoding
Two complementary encoders extract representations from the input speech waveform: Whisper provides semantic representations (ew) capturing linguistic content, while TRILLsson provides paralinguistic representations (et) capturing prosodic and acoustic cues. Each branch passes through a 1D-CNN block (filter size 3) and max-pooling, then projects into a shared Euclidean space of dimension d. A sigmoid gating module filters salient information before the hyperbolic mapping stage.
Hyperbolic Projection
Both representations are mapped into a d-dimensional hyperbolic space Hdc (curvature −c) via the exponential map at the origin:
Yielding hyperbolic representations hw and ht on the Poincaré manifold.
Hyperbolic Speech–Speech Alignment (H-BD-SS)
We minimize the Bhattacharya distance (BD) between the semantic and paralinguistic hyperbolic distributions to align them. For distributions P and Q on Hdc:
This yields the speech–speech alignment loss LS-S = DB(hw, ht). The aligned representations are then fused using Möbius addition (⊕c), which preserves hyperbolic geometry: hf = hw ⊕c ht.
Hyperbolic Speech–Prompt Alignment (H-BD-ST)
A conditioning prompt "Analyze the speech for unnatural artifacts" is fed to Qwen2-7B. Hidden states from an intermediate transformer layer are mean-pooled to obtain a prompt representation eA, projected to the shared space, then mapped to hyperbolic space. The same BD alignment is applied between the fused speech and prompt: LS-T = DB(hf, hA). Final aggregation: hfinal = hf ⊕c hA.
Frozen LLM Decoding
The aggregated hyperbolic representation is mapped back to Euclidean space via the logarithmic map, linearly projected to g, and injected as prefix conditioning tokens into the frozen Qwen2-7B decoder. A decision prompt "Determine whether the speech is real or fake. Answer only in one word: 'Real' or 'Fake'" drives generation of the output sequence Y. Training minimizes:
Whisper
OpenAI's speech recognition model; captures linguistic and semantic content from speech.
TRILLsson
Google's paralinguistic model; captures prosodic and acoustic non-semantic cues — key for deepfake detection.
Poincaré Ball (Hdc)
Hyperbolic space with curvature −c. Naturally embeds the hierarchical structure of speech semantics and artifacts.
Bhattacharya Distance
Extended to hyperbolic space for speech–speech and speech–prompt distribution alignment. Novel contribution.
Möbius Addition
Geometry-preserving operation in hyperbolic space. Fuses semantic + prosodic, and speech + prompt representations.
Qwen2-7B (frozen)
Prefix-conditioned generation with ~3.75M trainable parameters. Lightweight variant with Qwen2-1.8B also evaluated.